 |
 |
régŁș2024-06-23 íÔŽŁșșÏ·ÊŸWhfw.cc ŚśŐߣșhfw.cc ÎÒÒȘŒmće

|

|

|

|

|

|
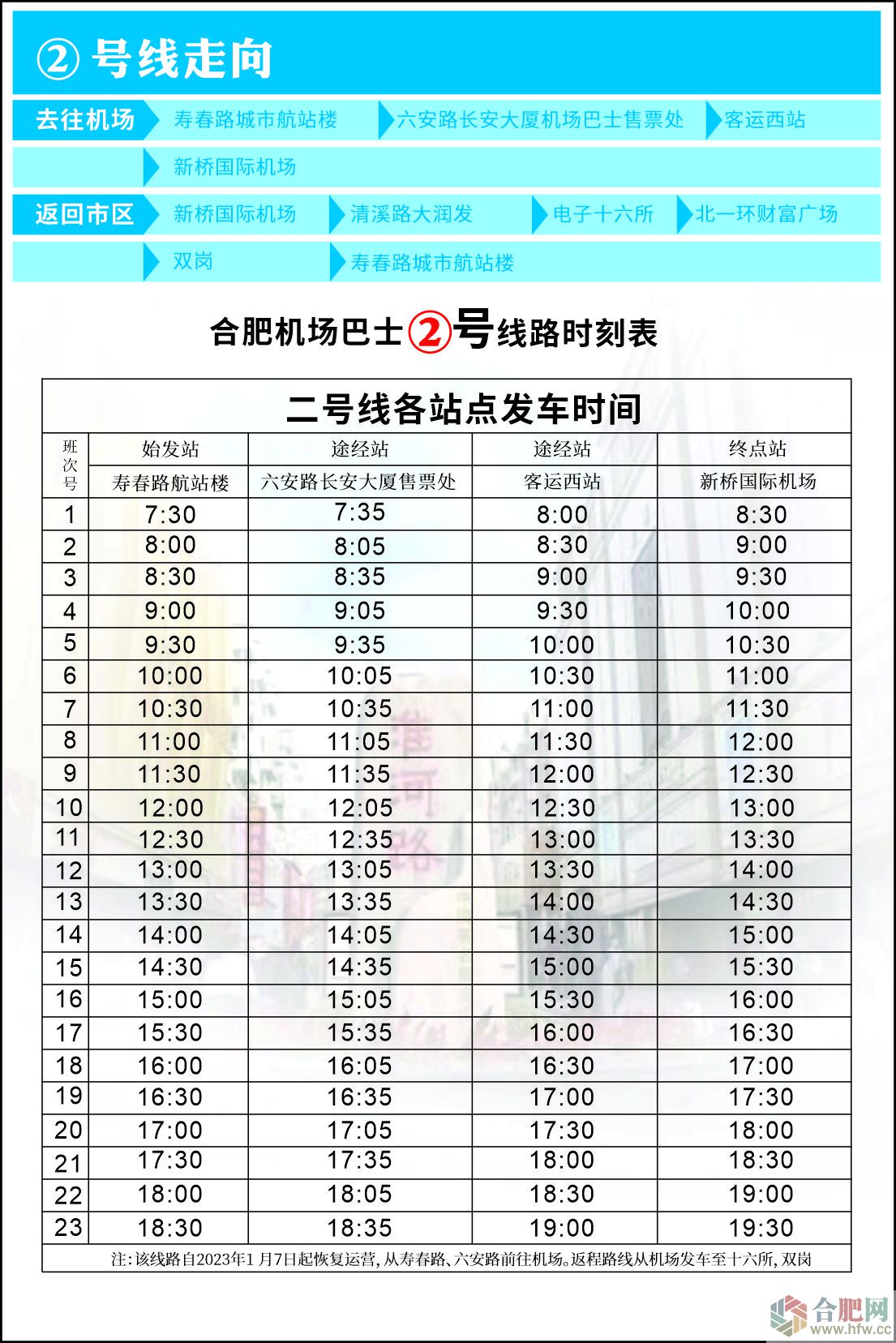
|
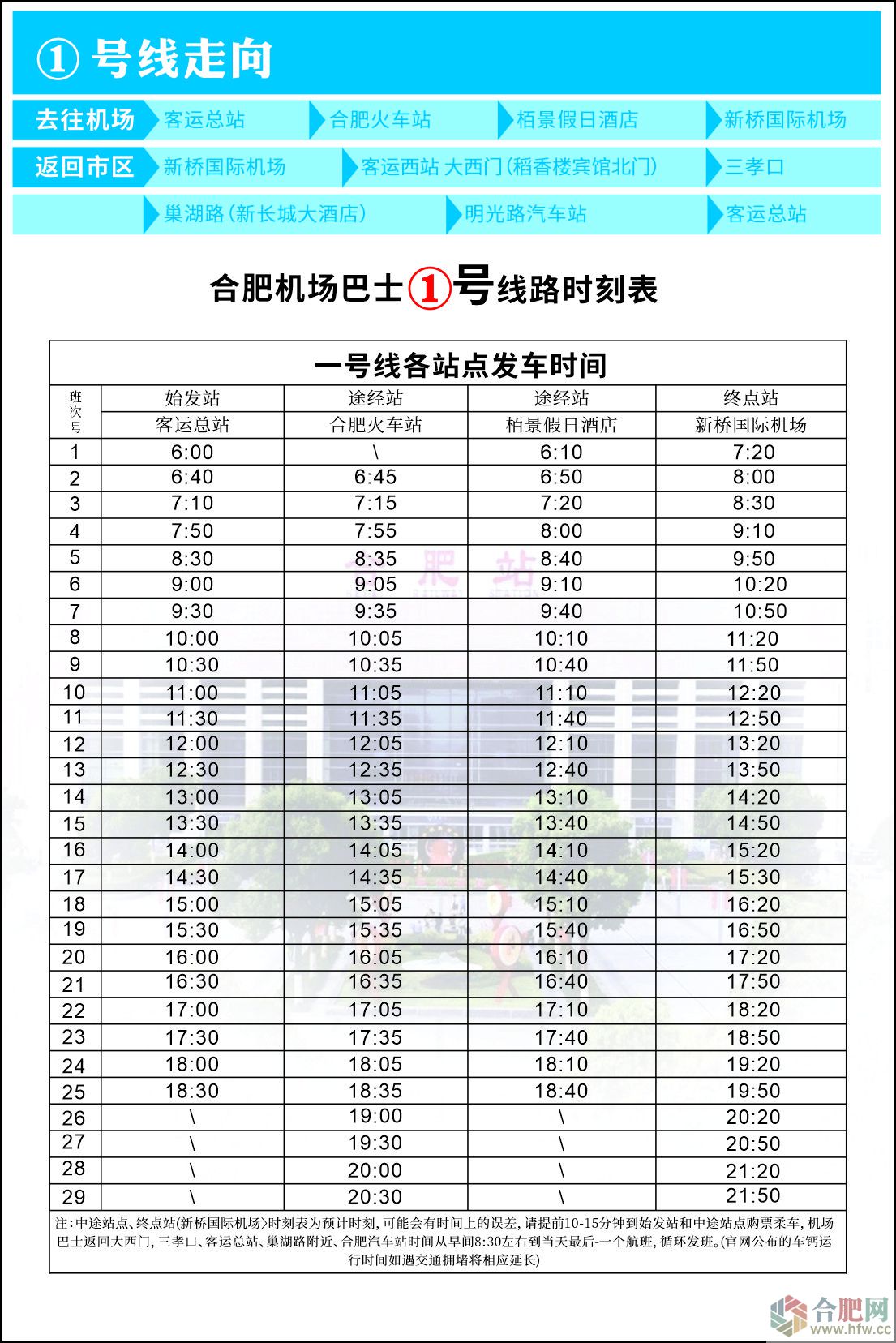
|
 |
¶ÌĐĆòŚCŽa ŸÆ”êviÔOÓ NBAֱȄ Ć°ČÏÂĘd
Copyright © 2025 hfw.cc Inc. All Rights Reserved. șÏ·ÊŸW °æàËùÓĐ
ICPä06013414Ì-3 č«°Čä 42010502001045

