 |
 |
rég£ŗ2025-01-07 ķŌ“£ŗŗĻ·Ź¾Whfw.cc ×÷Õߣŗhfw.cc ĪŅŅŖ¼måe

|

|

|

|

|

|
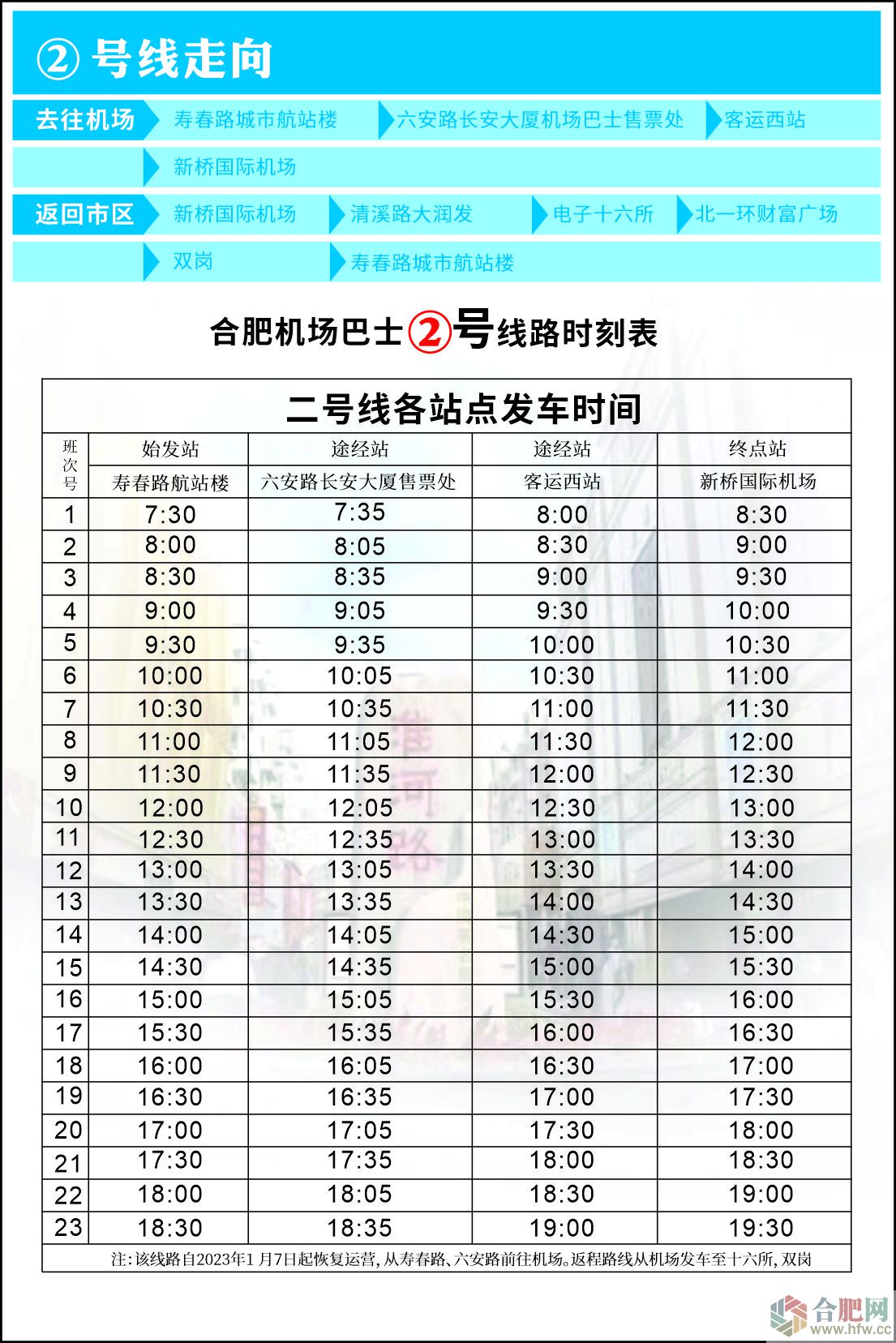
|
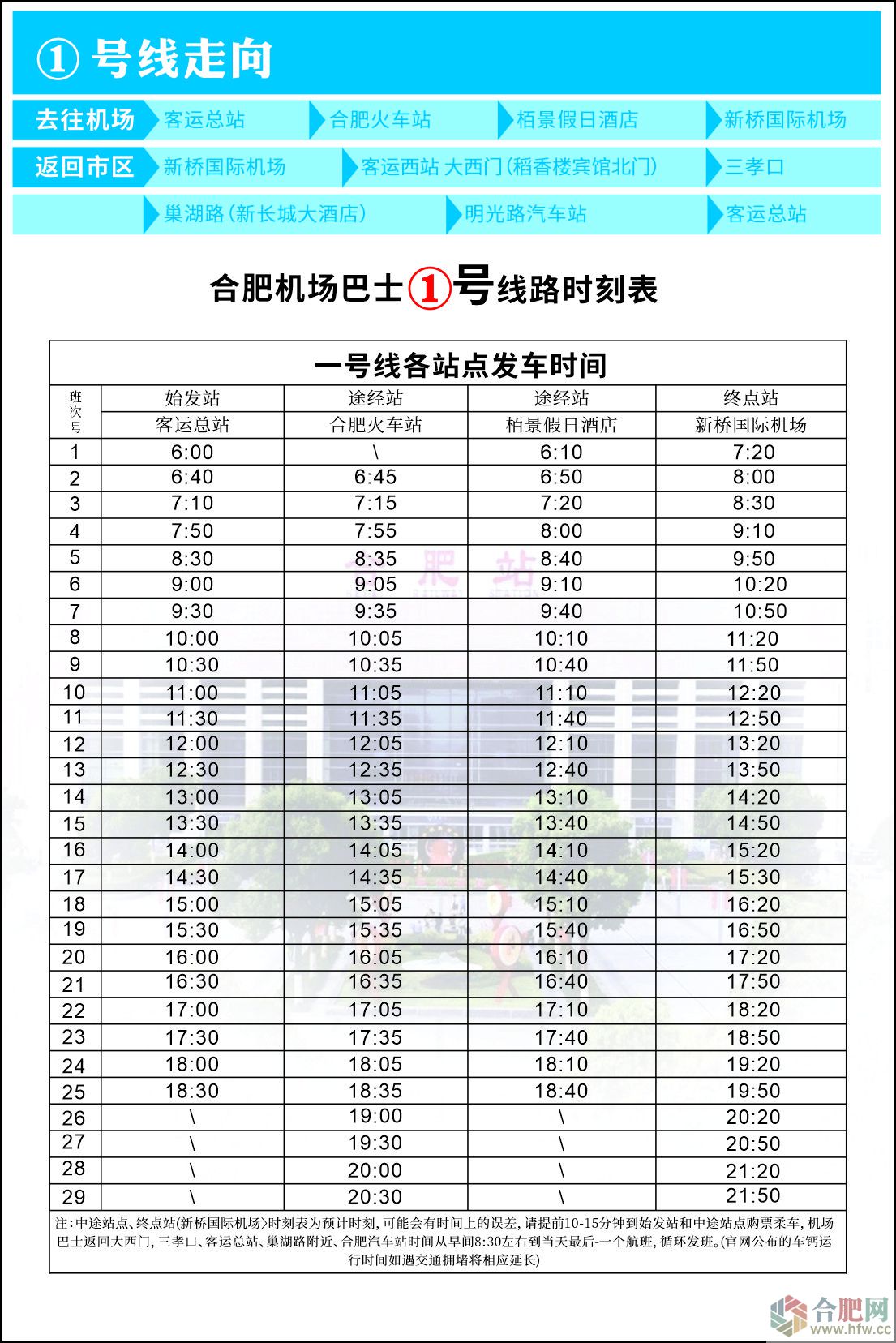
|
 |
¶ĢŠÅņ×C“a ¾ĘµźviŌOÓ NBAÖ±²„ Å°²ĻĀŻd
Copyright © 2025 hfw.cc Inc. All Rights Reserved. ŗĻ·Ź¾W °ęąĖłÓŠ
ICPä06013414Ģ-3 ¹«°²ä 42010502001045

